
Massive Problems (Part 1)
How to Avoid the Ticker Reincarnation Problem

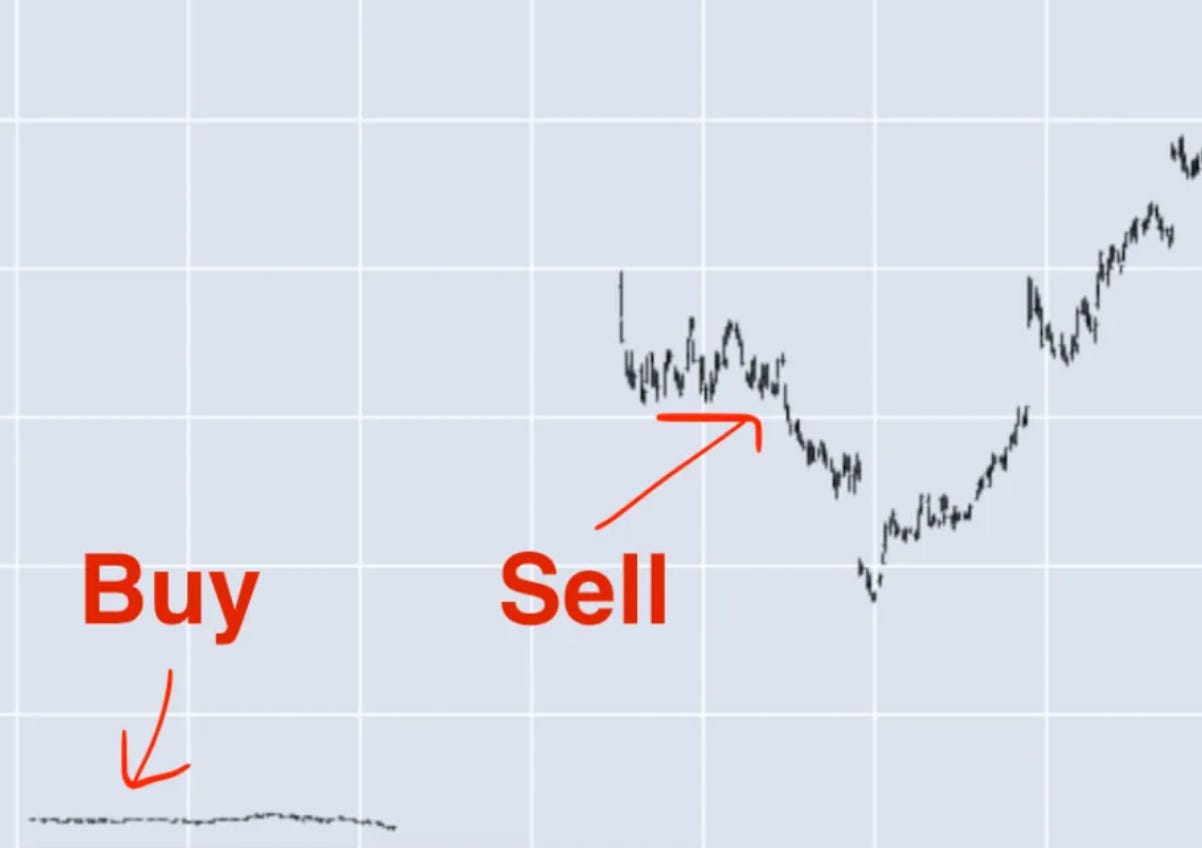
The equity curve went vertical.
No drawdowns.
No chop.
Just exponential gains.
The kind of backtest that makes you double-check the math.
Turns out the math was fine.
The history wasn’t.
I had just finished 8+ hours of downloading data from Polygon.
I ran a simple breakout strategy — nothing exotic.
It crushed.
A few trades in particular carried the entire equity curve.
For example-
I bought META early in the sample.
I sold META much later.
The backtested pnl was huge.
Except I didn’t buy and sell the same thing.
I bought META when it was a metaverse ETF.
I sold META when it was Facebook stock.
Same ticker.
Different issuers.
One very annoying bug.
My database treated it as a single, uninterrupted price series —
the same way a reverse stock split pretends value was created.
For the un expirienced eye it looked like alpha.
In reality, it was just bad identity resolution wearing a very profitable equity curve.
That’s when the real problem became obvious:
A ticker in Polygon is not a company.
What we’re actually trying to achieve
The goal here is to build a dataset that answers one precise question, correctly, for any historical date:
“What could I have traded on that day, and what exactly was it?”
If your database cannot answer that question unambiguously, then any backtest built on top of it is already compromised—regardless of how good the signal logic is.
More concretely, for systematic research we need three properties at the same time:
Point-in-time correctness
For any trading day, the universe must contain exactly the tickers that were listed and tradable on that day.
No survivors pulled from the future.
No delisted names silently removed.Identity continuity
A price series must belong to a single economic entity over its lifetime.
When a ticker is reused, history must break, not continue.Deterministic reconstruction
Given the same raw inputs, the universe membership and listing intervals should be reproducible and stable over time—no dependence on when the API happens to be queried.
You need historical truth.
Not what exists now, but what existed then.
So if you naïvely replay “active tickers” backward, you are implicitly assuming:
Companies don’t die
Tickers don’t get reused
Identity doesn’t matter as long as the string matches
That assumption is exactly what turned my META backtest into a work of fiction.
What we want instead is a minimal, boring, but correct abstraction:
Treat tickers as labels that change over time
Treat listings as time-bounded intervals
Treat daily snapshots as immutable facts
Build all higher-level logic (backtests, universes, factor exposures) on top of that
You need point-in-time membership and explicit identity boundaries.
Everything that follows—daily snapshots, master intervals, calendar-aware updates, and stricter matching rules—is just machinery to enforce those constraints.
The rest of this article is about building that machinery in a way that is:
correct first
fast enough second
and hard to accidentally break in production
The correct mental model: daily snapshots → master intervals
Think of each trading day having a set of active tickers for that day (plus metadata).
From snapshots, you build a Master Table of listing intervals:
start_date: first day the security appears in snapshots
end_date: last day it appears in snapshots
active flag: whether it is still active at the latest processed day
The algorithm:
Day 1: initialize Master Table with day 1, set start_date=day1 date, end_date=NULL
For each next day d2…dn:
Delistings: items in Master Table that were active but are not in day i → set end_date = day_{i-1}, mark inactive
New listings: items in day i that are not present in Master Table → append with start_date = d_i, active
Continuing: present in both → do nothing
This approach automatically preserves delistings and keeps membership consistent across time.
Special note: some companies register for 1-2 days as active, then go inactive and come back for IPO after a few months. You need to make sure your logic handles that.
Delistings, missing delisted dates, and why snapshots still work
The Polygon API often do not provide a reliable “delisted_utc” for every inactive ticker. I observed that many tickers can be active=False without having a delisted timestamp.
Snapshot-based logic is robust to that:
You infer delisting by absence from last day to current day instead of relying on delisted_utc.
The “end_date = previous trading day” becomes your authoritative delisting marker in your master list.
The tricky part: “same ticker” does not always mean “same company”
If you key identity purely on ticker, you will eventually merge two different issuers under one symbol.
So I adopted a stricter rule to decide “same company”, in this order:
Ticker must match (we only try to match within the same symbol)
If composite_figi is present on both rows and equal → same company
Else if cik is present on both rows and equal → same company
Else if rapidfuzz.token_set_ratio(name1, name2) >= 90 → same company
Otherwise → not the same company
This gives you a practical compromise:
FIGI/CIK are strong identifiers when available
fuzzy name matching is a fallback for sparse/dirty metadata
Important nuance: by requiring ticker equality first, we’re explicitly not trying to solve symbol changes (FB→META) inside this historical-ticker-list build step. That is a separate “renamings”/entity-resolution problem.
Our scope here is: for a given ticker symbol, detect when it represents a different entity.
One more nuance: some cik looks like this 947484.0 (float) and might change to this 0000947484 (string), while it’s still the same company. You want to normalize those before comparing.
Incremental updates: don’t rebuild history every day
Reprocessing thousands of daily files every run is unnecessary.
Incremental strategy:
Persist the master list on disk
On the next run:
load the master list
find the latest processed date from it
process only files after that date
for the “first new day”, use the master’s latest date as the “previous day” reference (this avoids relying on the presence/absence of specific files)
This makes daily operation cheap:
download today’s snapshot file
update master using only today’s file (compared against the master in memory)
write master back
Operational guidance: how to keep it correct in production
To keep the ticker list consistent over time:
Always store daily snapshots for trading days
don’t overwrite yesterday’s snapshot
treat snapshots as immutable audit logs
Build/maintain a master interval table
compute start/end dates from snapshots
use master as “source of truth” for what was processed
Update daily after market close
determine “target day” using market calendar
fetch snapshot
update master incrementally
Handle recycled tickers explicitly
don’t assume ticker uniquely identifies a company
use FIGI/CIK/name similarity to decide continuity within a symbol
What this gives you
With these practices you end up with:
a historical, point-in-time ticker universe suitable for backtests
correct delisting handling without relying on unreliable delisted timestamps
protection against symbol reuse corrupting your dataset
fast daily updates (incremental) and efficient storage (Parquet)
To make sure your master list is correct, you can compare the active tickers in your master list with the active list response from Polygon.
In my case I got a perfect match:
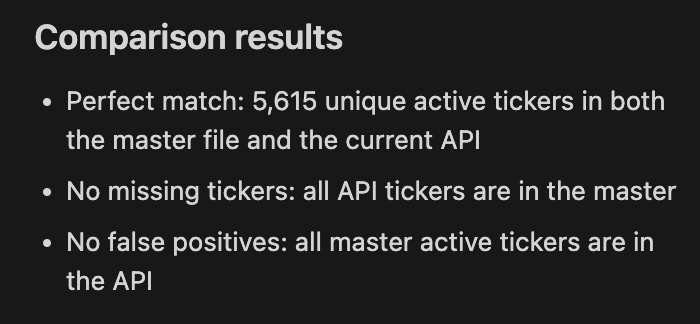
In the next parts I’ll explore how to adjust for splits, download and store data, aggregate candles and preapare the DB for fast backtests.
I love how the bullet points in, "So I adopted a stricter rule to decide “same company”, in this order:" are all 1. LOL!
Man after my own heart.
Hi Niv, how do you deal with spun offs?